신경망은 인간의 시냅스를 모델로 한 인공 신경망입니다.
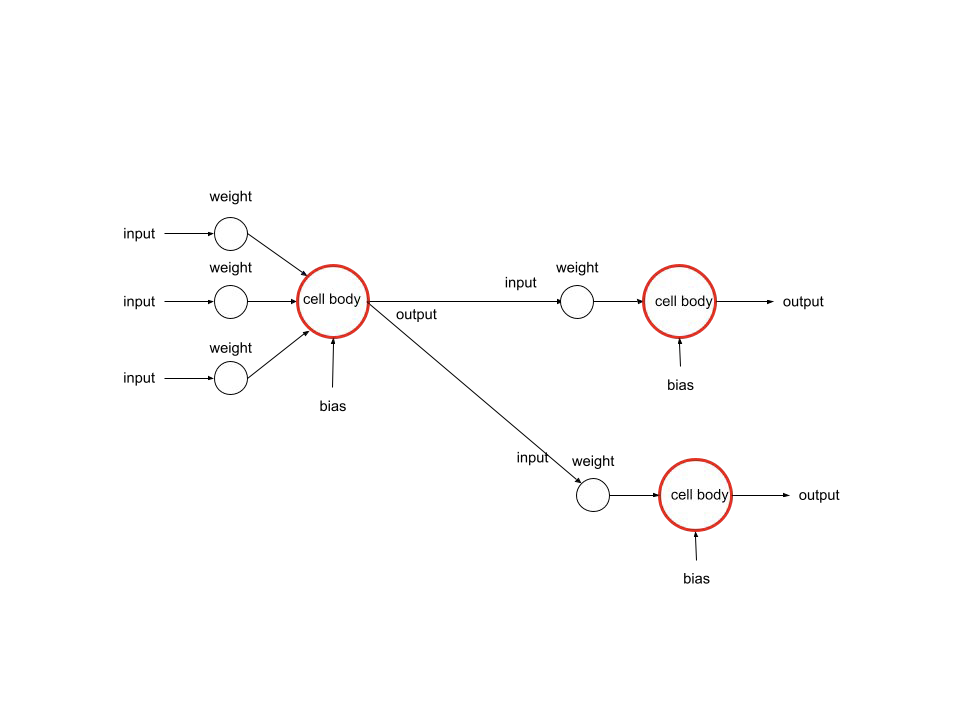
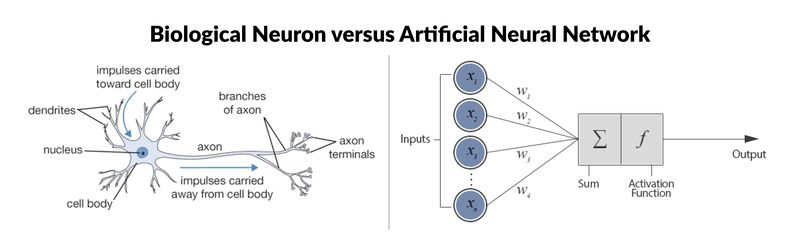
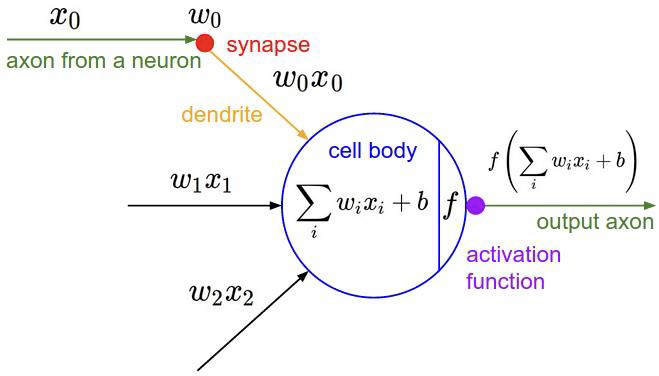
무게: 입력 값에 따른 중요도를 나타냅니다. 손실 함수가 최소화되는 방향으로 값이 수정됩니다.
가중 합계: 합계(입력값 * 가중치)를 의미합니다.
편견: 가중 합계에 추가되는 상수입니다. 처음에는 임의의 값으로 제공됩니다. 학습하는 동안 바이어스 값은 역전파를 통해 수정됩니다.
이는 손실함수를 최소화하는 방향으로 진행된다. 활성화 기능을 좌우로 움직여 다양한 학습이 가능합니다.
활성화 기능: 활성화 함수는 비선형성을 추가하여 복잡한 문제를 처리할 수 있도록 합니다. 신경망의 출력을 제한하여 모델의 안정성을 높입니다.
역전파 알고리즘: 편도함수를 사용합니다. 손실 함수의 기울기를 계산하고 각 가중치 및 편향에 대한 기울기를 계산합니다. 이를 바탕으로 가중치와 편향을 조정하고 손실 함수 값을 최소화합니다.
1. 입력 레이어에서 정방향 전파를 통해 출력 레이어의 출력 값을 계산합니다.
2. 손실 함수를 사용하여 출력 값과 실제 값의 차이를 계산합니다.
3. 출력 레이어에서 역방향으로 오류를 전파합니다. 이때 오차는 손실함수의 기울기에 활성화 함수의 기울기를 곱하여 구한다.
4. 이전 레이어로 이동하면서 가중치와 편향을 조정합니다. 가중치와 편향을 조정하는 것은 경사하강법과 유사합니다. 즉, 학습 속도와 기울기의 곱으로 현재 값에서 가중치와 편향을 조정합니다.
5. 위의 과정을 반복하여 손실 함수를 최소화하는 최적의 가중치와 편향을 찾습니다.
텐서플로우: 오픈 소스, 무료, Google Brain Team, 2015, 딥 러닝 프레임워크
딱딱한: 오픈 소스, 무료, 2.0부터 TensorFlow에 흡수됨, 쉬움
ML 모델링 과정:
데이터 준비(데이터 수집 및 전처리) -> 모델 설계(파라미터, 모델 선택) -> 모델 학습 -> 모델 평가
표준화: 데이터를 확장하여 모델 성능을 개선하고 과적합을 방지합니다.
모양 변경(): 데이터의 차원을 변경합니다.
원-핫 인코딩: 범주 데이터를 수치 데이터로 변환,
모델.요약(): 출력 모양, 레이어 및 매개변수 번호를 제공합니다.
매개변수: Keras 모델의 학습 가능한 매개변수 개수, 가중치 개수 + 편향 개수를 의미합니다.
바이어스 수 = 출력 뉴런 수
가중치 수 = 출력 뉴런 수 * 입력 뉴런 수
model = Sequential()
model.add(Dense(units=64, activation='relu', input_shape=(784,)))
model.add(Dense(units=10, activation='softmax'))
'''
첫번째 레이어 가중치 개수: 784 * 64
첫번째 레이어 편향 개수: 64
두번째 레이어 가중치 개수: 64 * 10
두번째 레이어 편향 개수: 10
'''손실 함수: 모델의 예측값과 실제값의 차이를 나타내는 함수. 낮추는 것을 목표로 훈련해야 합니다. (categorical_Crossentropy, mean_squared_error, binary_crossentropy)
옵티마이저: 가중치 및 절편과 같은 매개변수를 조정하는 방법을 제공하는 알고리즘입니다. 즉, 손실함수를 최소화하는 매개변수를 찾는 역할을 한다. (RMSprop, SGD, 아담)
메트릭:모델이 컴파일될 때 평가 메트릭을 지정하는 데 사용됩니다. 이러한 평가 메트릭은 모델이 훈련되는 동안 모니터링되며 모델의 성능을 평가하는 데 사용됩니다.
시대: 과도한 교육 시간과 에포크는 과적합을 초래합니다.
배치 크기: 한 번에 모델에 입력할 데이터의 크기입니다. 너무 작으면 노이즈가 많이 발생하고(업데이트가 자주 발생하기 때문에), 너무 크면 메모리에 부담이 됩니다.
데이터가 60000이고 배치 크기가 10이라고 가정합니다. 60000/10 = 6000개의 가중치와 바이어스가 에포크당 업데이트됩니다.
과적합: 교육 데이터 세트에 과적합된 모델입니다.